SEO Послуги
Ніякої магії, лише ефективна робота над сайтом!

Ніякої магії, лише ефективна робота над сайтом!
Результати та успіх наших замовників!
Ділимося найкориснішими порадами для маркетингу!
Жодної магії - лише кропітлива робота над проєктами.

Файл robots.txt часто не помічають. Або діють за принципом «не знав, не знав, та й забув».
Хоча саме robots.txt – важлива частина будь-якого набору інструментів SEO, незалежно від того, новачок ви в цій галузі або вже досвідчений ветеран-оптимізатор.
Файл robots.txt показує важливу інформацію для пошукових роботів, які сканують інтернет. Перед тим як перевірити всі сторінки вашого сайту, пошукові роботи перевіряють даний файл.
Robots.txt ще вказує пошуковій системі на те, які сторінки сканувати, а які ні. А ще це відмінний інструмент для управління краулінгового бюджету вашого сайту.
Ви, напевно, запитуєте себе: «Хвилиночку, а що взагалі таке краулінговий бюджет?» Краулінговий бюджет – це те, що використовує Google для ефективного сканування і індексації сайту. Яким би великим не був Google, у нього все ще замало ресурсів для сканування та індексування контенту такої кількості сайтів, яка є зараз.
Якщо у вашого сайту є всього лише кілька сотень URL, то Google без проблем зможе сканувати та індексувати сторінки вашого сайту.
Але якщо ваш сайт великий (як, наприклад, інтернет-магазин), і ви маєте десять тисяч сторінок з величезною кількістю автоматично згенерованих URL, тоді Google може не сканувати всі ці сторінки, і ви втратите купу потенційного трафіку.
Це саме той момент, коли потрібно підказати, що, коли і скільки потрібно сканувати.
В Google повідомили, що «наявність безлічі url-адрес з низькою якістю наповнення погано впливає на сканування та індексацію сайту». Ось де наявність файлу robots.txt може допомогти з факторами, що впливають на краулінговий бюджет вашого сайту.
Ви можете використовувати цей файл для управління краулінговим бюджетом, будучи впевненим, що пошукові системи використовують час на вашому сайті настільки ефективно (особливо якщо у вас великий сайт), наскільки це можливо, і що вони сканують тільки важливі сторінки і не витрачають час на такі сторінки, як сторінка входу, реєстрації або подяки.
Перш ніж пошуковий робот, такий, як Googlebot, Bingbot і ін., просканує веб-сторінку, він спочатку перевірить, чи існує насправді файл robots.txt. А вже якщо такий файл є, то пошуковий робот, як правило, буде слідувати вказівкам з цього файлу.
Файл robots.txt може бути потужним інструментом в будь-якому арсеналі SEO, оскільки це відмінний спосіб контролювати, як саме пошукові роботи/боти отримують доступ до певних частин вашого сайту.
Важливо! Ви повинні бути впевнені, що розумієте, як працює файл robots.txt, інакше ви випадково забороните роботу Googlebot або будь-якому іншому боту сканувати весь ваш сайт, і тоді ваш веб-ресурс не буде відображатися в результатах пошуку.
Але коли все зроблено правильно, ви можете контролювати такі речі, як:
Нижче наведу кілька прикладів того, як ви можете використовувати файл robots.txt на вашому сайті.
Дозвіл всім пошуковим системам/роботам на доступ до всього контенту вашого сайту:
User-agent: *
Disallow:
Блокування доступу всіх пошукових систем/роботів до всього контенту вашого сайту:
User-agent: *
Disallow: /
Ви можете побачити, що дуже легко припуститися помилки при створенні robots.txt для веб-ресурсу, коли відмінністю між блокуванням цілого сайту від дозволу повного доступу є лише слеш в директиві disallow (Disallow: /).
Блокування доступу певній пошуковій системі/роботу до певної папки:
User-agent: Googlebot
Disallow: /
Блокування доступу пошуковим системам/роботам до певної сторінці на вашому сайті:
User-agent:
Disallow: /thankyou.html
Заборона на доступ до певних папок сайту для всіх пошукових систем/роботів:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /junk/
Ось приклад того, як виглядає файл robots.txt на сайті theverge.com:
Ось так коректніше:
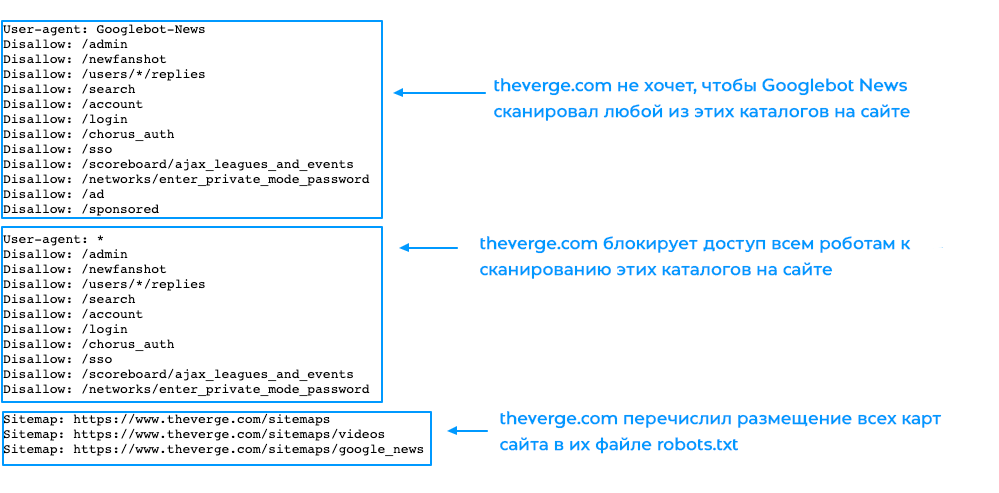
1 – theverge.com не хоче, щоб Googlebot News сканував будь-який з цих каталогів на сайті.
2 – theverge.com блокує доступ всім роботам до сканування цих каталогів на сайті.
3 – theverge.com перерахував розміщення всіх карт сайту в їх файлі robots.txt.
Цей же приклад файлу можна знайти тут: www.theverge.com/robots.txt.
В прикладі видно, як The Verge використовує файл robots.txt, щоб обмежити сканування певних каталогів на сайті новинним роботом Google «Googlebot-News».
Важливо пам'ятати, що якщо ви хочете бути впевнені, що боти не сканують певні сторінки або каталоги на сайті, то їх потрібно перерахувати в описі «Disallow» в вашому файлі robots.txt, як в прикладі вище.
Також ви можете більше дізнатися, як Google працює з robots.txt в їх інструкції згідно специфікації robots.txt. Google має максимальний ліміт на розмір файлу robots.txt – 500KB, отже важливо пам'ятати про розмір robots.txt на вашому сайті.
Створення файлу – досить простий процес, але в ньому дуже легко припуститися помилки. Не дозволяйте цьому перешкоджати вам створювати або модифікувати robots для вашого сайту. Ця довідка від Google розповість про процес створення файлу від і до, і допоможе з легкістю створити вам свій власний robots.txt.
Якщо ви освоїли правила створення і редагування robots, у Google є також рекомендаціїз поясненнями, як протестувати ваш файл robots.txt і перевірити, чи правильно він налаштований.
Якщо ви новачок в robots.txt, або не впевнені, чи є у вашого сайту такий файл, ви можете зробити швидку перевірку. Все, що вам потрібно, це перейти до домену вашого сайту і додати /robots.txt в кінець вашого URL. Наприклад: www.yoursite.com/robots.txt
Якщо нічого не відбувається, значить, у вас його немає. Тобто зараз саме час зайнятися його створенням.
Візьміть на замітку:
На що звернути увагу:
Якщо у вас є субдомен субдомен або кілька субдоменів на сайті, тоді вам потрібно мати файл robots.txt на кожному з них, так само, як і в основному домені. Виглядає це приблизно так: store.yoursite.com/robots.txt і yoursite.com/robots.txt.
Важливо пам'ятати, що краще не використовувати robots.txt для запобігання сканування такої інформації, як персональна інформація користувачів.
Причиною є те, що інші сторінки можуть посилатися на цю інформацію, і тоді з'явиться зворотнє пряме посилання, яке обійде правила файлу robots.txt, і тоді контент все одно може бути проіндексований.
Якщо вам потрібно заблокувати ваші сторінки від індексації в результатах пошуку, використовуйте різні методи, такі, як захист паролем або додавання метатега «noindex» на ці сторінки. Google не пройде на сторінку або сайт, захищений паролем, тому не зможе сканувати або індексувати ці сторінки.
Якщо не можете зробити самі, делегуйте
Якщо ви все ще трохи нервуєте, що ніколи раніше не працювали з файлом robots.txt, розслабтеся – він досить простий у використанні. Коли ви освоїте правила роботи з файлом, ви зможете поліпшити SEO вашого сайту, а також допомогти відвідувачам і роботам пошукових систем.
А якщо у вас не виходить, то завжди є СПРАВА. Допоможемо поліпшити видимість важливих сторінок вашого сайту! Звертайтеся!
Використовуючи robots.txt правильно, ви допоможете роботам пошукових систем витрачати їх краулінговий бюджет з розумом і сканувати тільки важливі сторінки. Тоді роботи не будуть витрачати час і ресурси на сторінки, які не потрібно сканувати. Це допоможе роботам організувати і показувати ваш контент в пошуковій видачі, що, в свою чергу, означає, що у вас буде найкраща видимість.
Не забувайте, що установка файлу не завжди вимагає багато часу. Здебільшого зробити це потрібно тільки один раз, а потім вже редагувати файл в залежності від ваших потреб.
Сподіваюся, що практики, поради та пропозиції, описані в цій статті, допоможуть вам бути більш впевненими в створенні/зміні robots.txt для вашого сайту, а також спростять процес роботи з файлом.
В нашому блозі ви можете також дізнатися від чого залежать ціни на просування сайту в Google.
Ми піклуємося про покращення ваших продажів :)