SEO Услуги
Никакой магии, только эффективная работа над сайтом!

Никакой магии, только эффективная работа над сайтом!
Результаты и успех наших заказчиков!
Делимся самыми полезными советами в маркетинге!
Никакой магии - только кропотливая работа над проектами.

Файл robots.txt часто не замечают. Или действуют по принципу «не знал, не знал, да и забыл».
Хотя именно robots.txt – важная часть любого набора инструментов SEO, независимо от того, новичок вы в этой отрасли или уже матерый ветеран-оптимизатор.
Файл robots.txt показывает важную информацию для поисковых роботов, которые сканируют интернет. Перед тем как проверить все страницы вашего сайта, поисковые роботы проверяют данный файл.
Robots.txt еще указывает поисковой системе на то, какие страницы сканировать, а какие нет. А еще это отличный инструмент для управления краулингового бюджета вашего сайта.
Вы, наверное, спрашиваете себя: «Минуточку, а что вообще такое краулинговый бюджет?» Краулинговый бюджет – это то, что использует Google для эффективного сканирования и индексации сайта. Как бы ни был велик Google, у него все еще маловато ресурсов для сканирования и индексирования контента такого количества сайтов, которое есть сейчас.
Если у вашего сайта есть всего лишь несколько сотен URL, то Google без проблем сможет сканировать и индексировать страницы вашего сайта.
Но если ваш сайт большой (как, например, интернет-магазин), и у вас тысячи страниц с огромным количеством автоматически сгенерированных URL, тогда Google может не сканировать все эти страницы, и вы потеряете кучу потенциального трафика.
Это именно тот момент, когда нужно подсказать, что, когда и сколько нужно сканировать.
В Google сообщили, что «наличие множества url-адресов с низким качеством наполнения плохо влияет на сканирование и индексацию сайта». Вот где наличие файла robots.txt может помочь с факторами, влияющими на краулинговый бюджет вашего сайта.
Вы можете использовать этот файл для управления краулинговым бюджетом, будучи уверенным, что поисковые системы используют время на вашем сайте настолько эффективно (особенно если у вас большой сайт), насколько это возможно, и что они сканируют только важные страницы и не теряют время на такие страницы, как страница входа, регистрации или страница благодарности.
Прежде чем поисковый робот, такой, как Googlebot, Bingbot и др., сканирует веб-страницу, он сначала проверяет, существует ли на самом деле файл robots.txt. А уж если такой файл есть, то поисковый робот, как правило, будет следовать указаниям из этого файла.
Файл robots.txt может быть мощным инструментом в любом арсенале SEO, поскольку это отличный способ контролировать то, как именно поисковые роботы/боты получают доступ к определенным областям вашего сайта.
Важно! Вы должны быть уверены, что понимаете, как работает файл robots.txt, иначе вы случайно запретите роботу Googlebot или любому другому боту сканировать весь ваш сайт, и тогда ваш веб-ресурс не будет отражаться в результатах поиска.
Но когда все сделано правильно, вы можете контролировать такие вещи, как:
Ниже приведу парочку примеров того, как вы можете использовать файл robots.txt на вашем сайте.
Разрешение всем поисковым системам/роботам на доступ ко всему контенту вашего сайта:
User-agent: *
Disallow:
Блокировка доступа всех поисковых систем/роботов ко всему контенту вашего сайта:
User-agent: *
Disallow: /
Вы можете увидеть, что очень легко допустить ошибку при создании robots.txt для веб-ресурса, когда различием между блокировкой целого сайта от разрешения полного доступа является лишь слеш в директиве disallow (Disallow: /).
Блокировка доступа определенной поисковой системе/роботу к определенной папке:
User-agent: Googlebot
Disallow: /
Блокировка доступа поисковым системам/роботам к определенной странице на вашем сайте:
User-agent:
Disallow: /thankyou.html
Запрет на доступ к определенным папкам сайта для всех поисковых систем/роботов:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /junk/
Вот пример того, как выглядит файл robots.txt на сайте theverge.com:
Вот так корректнее:
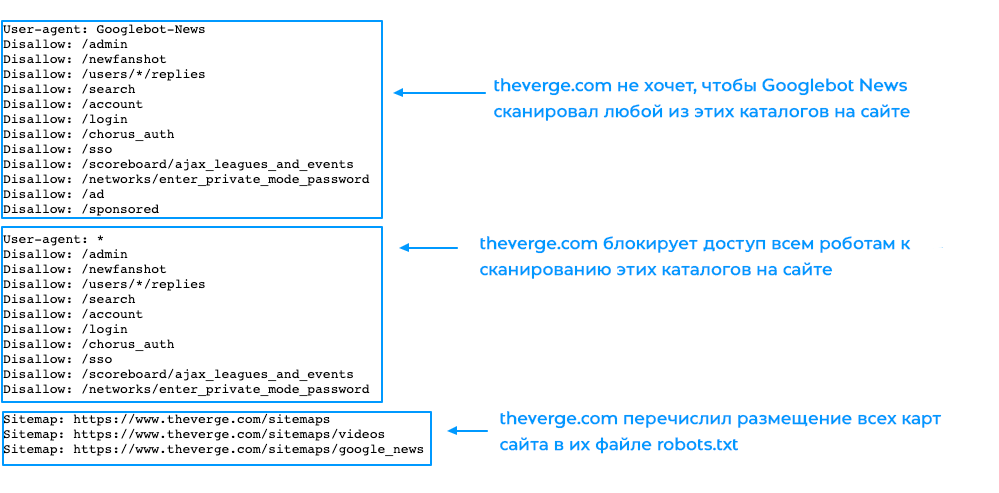
1 – theverge.com не хочет, чтобы Googlebot News сканировал любой из этих каталогов на сайте.
2 – theverge.com блокирует доступ всем роботам к сканированию этих каталогов на сайте.
3 – theverge.com перечислил размещение всех карт сайта в их файле robots.txt.
Этот же пример файла можно найти здесь: www.theverge.com/robots.txt.
В примере видно, как The Verge использует файл robots.txt, чтобы ограничить сканирование определенных каталогов на сайте новостным роботом Google «Googlebot-News».
Важно помнить, что если вы хотите быть уверены, что боты не сканируют определенные страницы или каталоги на сайте, то их нужно перечислить в описании «Disallow» в вашем файле robots.txt, как в примере выше.
Также вы можете больше узнать, как Google работает с robots.txt в их руководстве по спецификации robots.txt. Google имеет максимальный лимит на размер файла robots.txt – 500KB, так что важно помнить о размере robots.txt на вашем сайте.
Создание файла – достаточно простой процесс, но в нем очень легко допустить ошибку. Не позволяйте этому препятствовать вам создавать или модифицировать robots для вашего сайта. Эта справка от Google расскажет о процессе создания файла от и до, и поможет с легкостью создать вам свой собственный robots.txt.
Если вы освоили правила создания и редактирования robots, у Google есть также рекомендации, которые объяснят, как протестировать ваш файл robots.txt и проверить, правильно ли он настроен.
Если вы новичок в robots.txt, или не уверены, есть ли у вашего сайта такой файл, вы можете сделать быструю проверку. Все, что вам нужно, это перейти к домену вашего сайта и добавить /robots.txt в конец вашего URL. Например: www.yoursite.com/robots.txt
Если ничего не происходит, значит, у вас его нет. То есть сейчас самое время заняться его созданием.
Возьмите на заметку:
На что обратить внимание:
Если у вас есть субдомен или несколько субдоменов на сайте, тогда вам нужно иметь файл robots.txt на каждом из них, так же, как и в основном домене. Выглядит это примерно так: store.yoursite.com/robots.txt и yoursite.com/robots.txt.
Важно помнить, что лучше не использовать robots.txt для предотвращения сканирования такой информации, как персональная информация пользователей.
Причиной является то, что другие страницы могут ссылаться на эту информацию, и тогда появится обратная прямая ссылка, которая обойдет правила файла robots.txt, и тогда контент все равно может быть проиндексирован.
Если вам нужно заблокировать ваши страницы от индексации в результатах поиска, используйте разные методы, такие, как защита паролем или добавления мета-тега «noindex» на эти страницы. Google не пройдет на страницу или сайт, защищенный паролем, поэтому не сможет сканировать или индексировать эти страницы.
Если не можете сделать сами, делегируйте
Если вы все еще немного нервничаете, что никогда раньше не работали с файлом robots.txt, расслабьтесь – он достаточно прост в использовании. Когда вы освоите правила работы с файлом, вы сможете улучшить SEO вашего сайта, а также помочь посетителям и роботам поисковых систем.
А если у вас не получается, то всегда есть СПРАВА. Поможем улучшить видимость важных страниц вашего сайта! Обращайтесь!
Используя robots.txt правильно, вы поможете роботам поисковых систем расходовать их краулинговый бюджет с умом и сканировать только важные страницы. Тогда роботы не будут тратить время и ресурсы на страницы, которые не нужно сканировать. Это поможет роботам организовать и показывать ваш контент в поисковой выдаче, что, в свою очередь, означает, что у вас будет лучшая видимость.
Не забывайте, что установка файла не всегда требует много времени. По большей части сделать это нужно только один раз, а потом уже редактировать файл в зависимости от ваших нужд.
Надеюсь, что практики, советы и предложения, описанные в этой статье, помогут вам быть более уверенными в создании/изменении robots.txt для вашего сайта, а также упростят процесс работы с файлом.
Мы заботимся о повышении ваших продаж :)